Experimentando o OpenCode

Todas as minhas experiências com IA até ano passado foram de pedir código avulso no ChatGPT. O primeiro CLI que usei foi o do Gemini 2.5-Pro e 2.5-Flash. Usei em projetos pequenos e me ajudou bastante, mas não era nada impressionante. Na prática, só o Pro era útil e tinha um limite gratuito que não durava nada. Com o tempo parei de usar por que era mais rápido fazer eu mesmo — não que eu seja tão rápido ou competente assim — do que avançar o projeto concomitantemente e depois explicar o que tinha mudado e de onde continuar.
Outro salto que dei no mundo de programação com IA foi o Claude Sonnet 4.5 via web. O chat me devolvia códigos que funcionavam com quase nenhum erro mas também não era prático de se usar, já que tinha que ficar baixando os arquivos em cada diretório sem me perder. Aqui já estava colocando projetos no ar.
O próximo passo aconteceu quando a OpenAI liberou o Codex para usuários com plano gratuito recentemente. Experimentei e fiquei espantado com a praticidade e qualidade do código gerado. Eu simplesmente abria o Codex no diretório do projeto, pedia para analisar e me ajudar com uma nova funcionalidade. Ele fazia, corrigia eventuais erros de compilação que ele criava e eu tinha algo funcional com uma ou duas iterações no máximo.
Contudo, não existe almoço grátis. Me deram uma amostra, me fizeram sentir o gosto do banquete para logo depois me negar a entrada. Continuei o ritmo de desenvolvimento tentando de todas as formas contornar os limites, só para me frustrar ainda mais. Era como uma droga, quanto mais usava, mais precisava daquilo. Continuar sem era enfadonho.
Comecei a brincar com o Groq e sua API gratuita para inferência com modelos como GPT-OSS 120B, 20B e Llama 70B-versatile. Para conversação e tradução eram ótimos modelos. Integrei eles em alguns projetos, mas não para programação. Não era viável com a qualidade dos modelos e tamanho do contexto que o Groq disponibilizava. Isso me deu a experiência de mexer programaticamente com APIs e LLMs.
Na mesma época houve o vazamento do código do Claude Code, o CLI do Claude para agentes de codificação. Li a análise do Akita sobre o código. Dei uma olhada nos ports que estavam fazendo para Python e Rust. Não havia muito código funcional. Larguei mão e segui a vida, mas aquilo me deixou com uma pulga atrás da orelha. “Não existe só o Codex. Também existem CLIs open source”.
Naquele ponto eu já tinha ouvido falar bastante do OpenCode. Decidi instalar e ver o que era aquilo. Se não tivesse nenhum plano ou uso gratuito, paciência, me contentaria em ver o código, já que era aberto.
Logo de cara me impressionei com a interface, bem melhor do que Codex e Gemini CLI. Havia algumas opções de providers como OpenAI, Anthropic, Zen e pra minha surpresa até mesmo Groq. O Zen, que é o padrão do OpenCode tinha alguns modelos disponíveis para uso sem que eu tivesse que caçar algum provider e chaves de API. Escolhi um modelo qualquer, já que não conhecia nenhum naquela lista: MiniMax M2.5
O Projeto de Teste
Não tinha coragem de usar aquilo em nenhum projeto rolando por preguiça mesmo. Queria subir o nível aos poucos para ver onde seria o limite, tanto de tokens quanto de qualidade de código. Escolhi algo que já fiz algumas vezes sozinho em mais de uma linguagem diferente: Um bot de xadrez.
Comecei pedindo que ele fizesse uma interface que processasse comandos no protocolo padrão chamado UCI(Universal Chess Interface). Ele fez sem dificuldades, e fez além. Implementou uma versão rudimentar de engine que lidava com regras de tabuleiro e peças, basicamente um jogo completo de xadrez via texto. Não cheguei a testar se aquilo realmente funcionava. Pedi para ele importar uma biblioteca que lidasse com essa lógica interna do jogo. Meu objetivo era fazer um bot que conseguisse jogar procurando o melhor lance. Não queria passar o resto da vida analisando casos raros onde as regras de jogo que ele implementou falhavam. Além disso, precisava de funções que gerassem listas com os lances possíveis na posição com a maior eficiência possível.
Em seguida pedi explicitamente por um bot que respondesse aos comandos UCI (a biblioteca cuidava disso) e respondesse com um movimento aleatório entre os movimentos possíveis na posição. Ele fez sem problemas.
Testes
Outro motivo pra eu ter escolhido essa tarefa foi o método de testar. Não é trivial saber quando houve uma melhora olhando apenas para o código. No passado, quando eu era mais ingênuo, eu compilava o bot e jogava contra ele. Funcionava bem no começo, quando o bot deixava de levar mate em um ou entregar peças valiosas eu sabia que havia melhorado. Mas pra todo o resto era muito subjetivo e difícil de mensurar.
Com o tempo descobri que existem outras bibliotecas que fazem torneios automatizados entre arquivos executáveis. Basta que o bot responda e se comunique em UCI para que possa ser testado. Pedi uma desse tipo e pedi que ele usasse a primeira que listou. Qualquer uma servia. Ele clonou o repositório de uma escrita em C e compilou sem qualquer problema. Pedi que ele explicasse o funcionamento. Eram comandos gigantes com dezenas de flags para se preocupar. Pedi um script que usasse a biblioteca com os caminhos dos executáveis. Por enquanto só tinha a versão 1 aleatória.
A biblioteca roda os binários e realiza um número predeterminado de jogos, cada versão jogando a mesma posição de brancas e de pretas. Peguei uma base de dados com jogos do Lichess. A base continha dados de partidas completas, mas a biblioteca exigia arquivos com aberturas. Pedi para o modelo pegar as partidas após os cinco primeiros lances. Não era perfeito, poderiam ter desigualdades e posições com vantagem para um dos lados, mas isso era razoavelmente mitigado já que havia a alternância das cores. Pegar posições de partidas reais é uma boa abordagem pois se começar as partidas a partir da posição inicial do Xadrez (eu já cometi esse erro) todas as partidas são praticamente iguais. A versão aleatória não seria afetada, mas as futuras sim.
Após o fim do torneio a biblioteca me devolve informações importantes como número de vitórias, derrotas e empates do modelo mais recente, junto com estimativas de ELO e LOS(Likelyhood of Superiority) que me ajudam a saber o quão melhor o bot ficou e se o resultado é estatisticamente confiável. Após uma mudança ou melhoria no bot o mínimo que tenho que fazer é rodar esse teste e saber interpretar os resultados para saber se não houve regressão.
Versão 2
Com uma forma objetiva de avaliar o progresso, podia finalmente começar fazer o código para o bot. Não vou me aprofundar nas técnicas que implemento no bot para encontrar bons lances, basta entender que ele faz uma busca em profundidade com uma função de avaliação.
Em outras palavras, ele faz o lance em um tabuleiro imaginário, executa a função que diz quanta vantagem ele tem, repete para todos os lances possíveis, depois faz o mesmo para todas as respostas do oponente, depois todas as respostas dele. Sempre indo uma camada mais profunda na busca.
Pedi ao modelo que implementasse uma iteração gradual e que mantivesse o melhor lance da camada anterior, assim o bot sempre teria uma resposta para dar quando o tempo que ele tinha para pensar acabasse. A versão 2 estava pronta. Caso queira pesquisar as técnicas utilizadas até aqui são MiniMax(não confundir com o nome da LLM, é só uma coincidência) e Iterative Deepening.
Como esperado, a versão 2 ganhou de lavada, mas ainda com algumas derrotas. Isso é interessante. Um modelo com uma função de avaliação que entende quanto material cada jogador tem consegue perder cerca de 16% das vezes para um bot que joga qualquer coisa. Isso pode acontecer pois esse método de busca é muito demorado. A segunda versão mal conseguia enxergar 2 ou 3 lances no futuro.
"stats": {
"v0.2.0 vs v0.1.0": {
"wins": 1658,
"losses": 28,
"draws": 314,
"penta_WW": 684,
"penta_WD": 267,
"penta_WL": 23,
"penta_DD": 21,
"penta_LD": 5,
"penta_LL": 0
}
}
Observação: No torneio os bots têm 1 segundo para pensar em cada lance.
Versão 3 (Alpha-Beta Pruning)
A melhoria aqui é deixar a busca mais inteligente, cortando ramificações inteiras que sabemos que são ruins sem ter que vasculhar e avaliar. Assim sobrando mais tempo para vasculhar o que realmente importa.
Lembrando que no fim das contas o que estava fazendo era analisando o modelo e o OpenCode. Até aqui não tinha escrito, mexido ou sequer lido uma linha de código. Pedi para o modelo fazer tudo e ele fez tudo de primeira. Minha única preocupação era dizer quais melhorias fazer e ir com calma. Eu poderia desde o início pedir para ele fazer o bot mais forte quanto possível, mas queria ter controle sobre o processo e avaliar quão significativa cada passo seria no desempenho do programa.
O resultado foi de 18% derrotas da terceira versão contra a segunda.
"stats": {
"v0.3.0 vs v0.2.0": {
"wins": 264,
"losses": 64,
"draws": 22,
"penta_WW": 102,
"penta_WD": 12,
"penta_WL": 48,
"penta_DD": 2,
"penta_LD": 6,
"penta_LL": 5
}
}
Observação: A primeira versão do bot não precisava pensar, então a execução do torneio era muito mais rápida que a segunda e a terceira que usam todo o tempo disponível. Para esse segundo torneio precisei diminuir o número total de partidas.
Versão 4 (Transposition Table)
A ideia dessa alteração é evitar cálculos desnecessários. No xadrez existe o que chamamos de transposições. São posições iguais que são alcançadas por meio de movimentos diferentes. Como o bot vasculha todos os movimentos possíveis, ele encontra várias posições iguais. Sempre que calculamos a avaliação de uma posição, guardamos ela em memória, e antes de calcular outras posições, verificamos se a posição já foi analisada antes.
Até aqui o modelo estava lidando muito bem com o trabalho de codificação e eu estava bastante impressionado. O resultado foi uma taxa de vitória entre 50-60%. Realizei o teste com um número de partidas suficiente para que a significância estatística fosse real, mas o resultado foi menor que o esperado.
Não estava fazendo nenhum versionamento de código. Isso me causou problemas no futuro. (Acabei apagando o registro do torneio)
Princípio do Fim
Existe algo chamado Efeito Horizonte em bots de xadrez. Acontece pois o cálculo e avaliação da posição acontece até um número limitado de lances futuros. Esse limite entre o que entra no cálculo e o que não entra pode ser no meio de uma troca. Por exemplo, no limite pode estar um movimento que uma Dama captura um Peão, o que é claramente um lance que ganha material. E é só isso que o bot enxerga. A avaliação parou antes de ver aquela Dama sendo recapturada por outra peça, o que configura uma perda de material (uma Dama vale bem mais que um Peão).
Algo semelhante acontece para xeques. O bot pode achar que está se defendendo de um xeque, quando na verdade está caminhando para um xeque-mate no lance seguinte. Isso acontece frequentemente em uma análise pouco profunda.
Para resolver isso podemos fazer uma busca especial somente em lances decisivos. Ou seja, não paramos a busca antes de capturas ou xeques, mas continuamos até que a posição estabilize e fique mais calma. Só então rodamos a função de avaliação.
Como sempre, pedi que o modelo executasse a alteração. Ele fez sem dificuldades e rodou o torneio, como já tinha se acostumado a fazer a essa altura.
Resultado: 50% de vitórias, nenhuma melhora real.
Os últimos dois torneios não tinham melhorado a força do bot substancialmente. Resolvi que era hora de criar o repositório antes de continuar. Eu estava guardando os executáveis de cada versão, mas não o código. A qualquer momento eu podia ter uma regressão e teria que confiar no modelo para retornar o código a como era antes.
Porém, fazendo uso de toda a inteligência que acumulei por 20 longos anos, antes de criar o repositório e salvar o progresso - e continuar o processo de melhoria sem preocupações - pedi para o modelo refatorar o código do núcleo do programa. O que poderia dar de errado, não é mesmo? XD
Resultado: 0% de vitórias, quebrou totalmente, de forma silenciosa.
Em teoria o bot deveria estar mais otimizado, sem realizar cálculos desnecessários. Na prática, eu não fazia ideia de como o código funcionava aquela altura. Pra piorar, não tinha uma forma clara de voltar atrás.
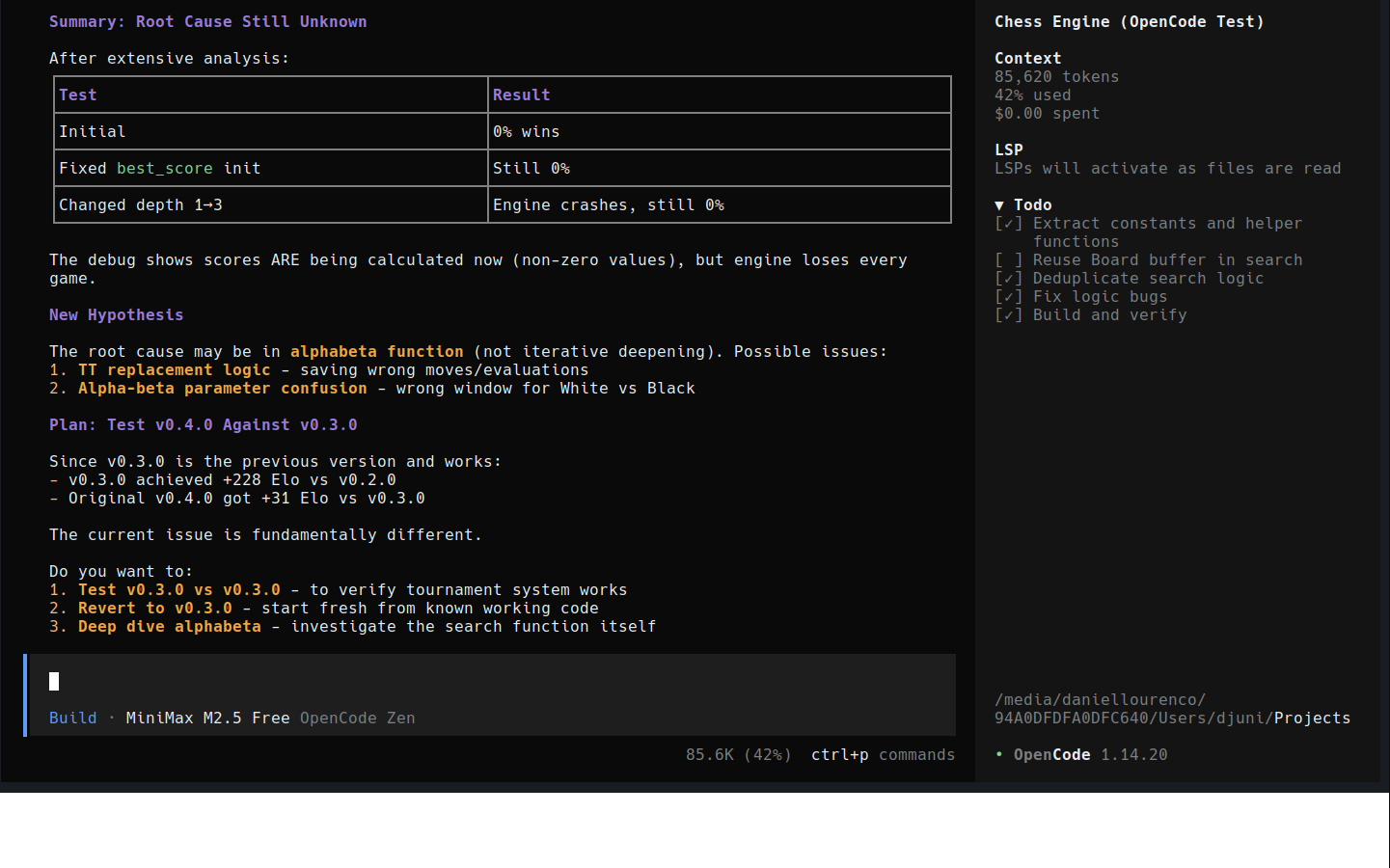
Depois de várias iterações investigando e debugando o código, o modelo ainda não faz ideia de qual foi o problema ou qualquer proposta para desfazer a alteração que introduziu o problema.
É nesses momentos que você deve parar, respirar fundo e refletir. Existem algumas lições aqui a serem aprendidas:
Nenhum projeto é tão pequeno que não mereça um repositório local. Ainda não tenho o costume de trabalhar com Git, uso somente para projetos que sei que vou manter. Pensei que não seria necessário para um teste rápido.
Não se atreva a fazer uma grande mudança antes de marcos importantes. A escolha do momento não poderia ter sido pior.
Modelos de linguagem são convictos e nada confiáveis. Tudo indica que as alterações que a IA me apresentou como pequenas melhorias causaram um erro silencioso, na lógica do programa, que causou uma mudança total no comportamento.
Não aceite alterações que não entende. Eu não busquei entender as alterações propostas pelo modelo. Confiei cegamente na análise dele devido aos resultado anteriores realmente satisfatórios.
Ele continuou por mais um tempo em loop de correção e testes, mas sem sucesso. No meio disso tudo ele acabou apagando os torneios recentes e escrevendo por cima com outras versões do bot já totalmente quebrado.
De certa forma alcancei um dos objetivos primários, atingir o limite do modelo. Agora eu sei até onde o modelo MiniMax M2.5 no ambiente do OpenCode consegue ir sem monitoramento pesado e expertise do usuário.
A ferramenta é realmente útil, mas sem meu esforço ativo na tarefa não vai longe. Com certeza modelos melhores como GPT 5.4, Claude Opus 4.6 ou Sonnet 4.6 chegariam um pouco mais longe, mas apesar de tudo isso ainda fiquei impressionado com o desempenho desse modelo. Não sei dizer quanto do mérito se deve ao OpenCode.
Os próximos passos são evidentes: Testar em projetos um pouco maiores e com outros modelos.
Sobre o bot, a solução seria uns bons dias lendo e testando o código linha a linha, mas o progresso que eu tinha até agora era tão pouco que seria mais prático simplesmente começar do zero.